이 글은 이유한님의 글을 참고하며 스스로 공부를 위해 더 자세하게 작성한 글 입니다.
(출처: 캐글 코리아 홈페이지의 이유한 님의 글)
학습을 위해 글을 작성하다보니 코드 하나에 깊게 파고드는 경우가 있을 것 같습니다. 참고해주시면 감사하겠습니다.
타이타닉 코드의 초반부인 탐색적 데이터 확인을 진행 하고 있습니다.
갈길이 아직 멀지만, 차근 차근 한걸음씩! 타이타닉과 Kaggle을 알아가보겠습니다 :-)
1. 탐색적 데이터 확인
1.2 Target Label 확인
- 가장 중한 생존에 대한 분포를 확인하고, binary classification 문제의 경우 이 분포에 따라 모델의 평가 방법이 달라질 수 있다고 합니다.
- 이 부분은 불러온 데이터를 활용하여 matplotlib.pyplot 모듈(패키지)을 사용한 pie plot 그래프와, seaborn 모듈을 사용한 count plot을 그리는 부분 입니다.
f, ax = plt.subplots(1, 2, figsize=(12, 4))
df_train['Survived'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('Pie plot - Survived') # X축 이름 넣기
ax[0].set_ylabel('') # y축 라벨 없애기
sns.countplot(x='Survived', data=df_train, ax=ax[1])
ax[1].set_title('Count plot - Survived') # X축 이름 넣기
plt.show()
결과
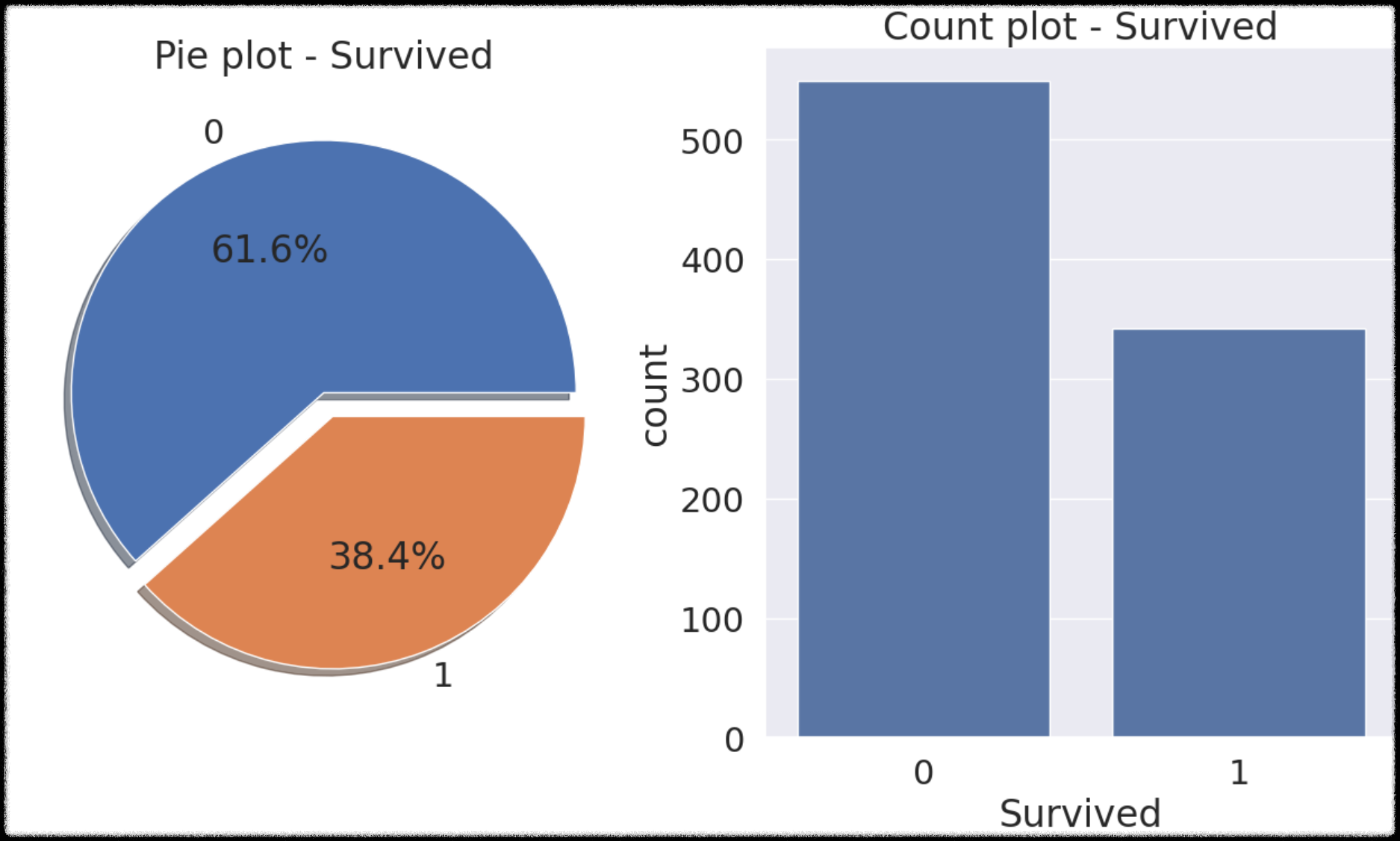
코드를 한 문장씩 dive해보면
1. f, ax = plt.subplots(1, 2, figsize=(12, 4)) 에서 f는 figure 객체를 저장하는 변수 이고, ax 는 Axes('축'을 나타내는) 객체들을 저장하는 리스트 입니다. plt는 matplotlib 모듈에서 pyplot 을 불러오고 plt의 약자로 사용하자고 위에서 약속했던 부분을 불러와서, subplot 그래프를 그릴 밑바탕(1행 2열의 서브플롯 그리드)을 생성합니다. figsize는 옵션으로, 가로 세로의 너비를 나타내는데, 여기서는 12inch ,4inch 를 나타냅니다.
2. df_train['Survived'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
- 두번째 줄의 코드 입니다.
- 앞부분의 df_train['Survived'].value_counts()부터 하나씩 확인해보면 df_train 데이터 셋에서 ['Survived'] 컬럼을 선택하고, value_count() 함수를 출력해보면 아래와 같이 나옵니다.
- 생존자의 수 = 1, 생존하지 못한 사람들의 수 = 0으로 나오는군요. 이 데이터를 사용해서 pie plot 그래프를 그립니다. pie플롯은 아래의 왼쪽 동그란 파이 모양의 그래프 입니다.

다음은 파이그래프의 옵션의 코드라인 입니다.
.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
explode=[0, 0.1] 각 항목을 파이의 원점에서 튀어 나오는 정도를 나타냅니다.
autopct='%1.1f%%' 각 항목의 퍼센트를 표시 합니다.
ax=ax[0] 0번 축에 데이터를 넣습니다.
shadow=True 그림자를 추가합니다.
3. ax[0].set_title('Pie plot - Survived') 파이플롯 제목을 'Pie plot - Survived'로 추가합니다.
4. ax[0].set_ylabel('') y축 라벨을 ('')으로 만들기 (삭제하기)
5. sns.countplot(x='Survived', data=df_train, ax=ax[1]) 에서 sns 는 seaborn 모듈의 countplot을 그립니다. 여기서 조금 헤멨었는데, 예전 seaborn 버전에서는 x=를 쓰지 않아도 자동으로 입력이 되었던 모양입니다. 아마 이유한님이 2019년에 올리셔서 그동안 모듈이 업데이트 되면서 여러가지가 바뀐 것 같습니다. (참고)
6. ax[1].set_title('Count plot - Survived') set_title() 함수로 타이틀에 이름을 ' Count plot - Survived' 으로 추가합니다.
7. plt.show() 그래프를 그립니다.
참고로 sns(seaborn 모듈 홈페이지를 참고한다면 자세한 내용을 확인할 수 있습니다.)
seaborn.countplot 옵션을 찾아보았습니다.
seaborn.countplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, fill=True, hue_norm=None, stat='count', width=0.8, dodge='auto', gap=0, log_scale=None, native_scale=False, formatter=None, legend='auto', ax=None, **kwargs)
seaborn.countplot — seaborn 0.13.2 documentation
seaborn.countplot seaborn.countplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, fill=True, hue_norm=None, stat='count', width=0.8, dodge='auto', gap=0, log_scale=None, native_s
seaborn.pydata.org
2. 탐색적 데이터 분석
- NaN 값이 얼마나 되는지 확인했는데, 다음은 탐색적 데이터 분석을 통해 데이터에 숨어있는 사실들을 찾아보는 시간입니다. 이러한 사실을 찾기 위해서는 데이터의 시각화가 필요합니다.
- 여기서 사용하는 데이터 시각화 툴은: pandas, matplotlib, seaborn을 사용해 데이터를 시각화하여 분석합니다.
- 모든 컬럼의 데이터[ PassengerId , Survived, Pclass, Name, Sex, SibSp, Parch, Ticket, Fare, Cabin, Embarked ] 항목을 하나하나 뜯어보면 좋겠군요.
2-1. Pclass 티켓 클래스
Pclass 컬럼을 확인해볼텐데, Pclass는 티켓의 class를 나타냅니다. 모든 값은 1, 2, 3으로 구성되어있는데 각 값은 1등석, 2등석,3등석을 나타내는군요.
이번에는 pandas 라이브러리의 crosstab을 사용합니다. crosstab은 파이썬에서 테이블 교차표를 만들 수 있는 툴 입니다. 함수에 행과 열 모두에 대한 합계를 포함합니다.
pd.crosstab(df_train['Pclass'], df_train['Survived'], margins=True).style.background_gradient(cmap='summer_r')결과 : margins=True 옵션 사용

margins=True 옵션 사용하지 않았을 경우

- 'Pclass'로 그룹화하여 mean()을 사용하면 클래스 별 생존률을 얻을 수 있네요.
- 'Pclass', 'Survived' 컬럼 데이터를 선택하고, groupby()함수로 'Pclass' 컬럼을 그룹화하고 mean()을 사용하면 pandas의 bar plot을 사용하는 모습입니다.
(마치 Database를 사용해서 데이터를 조회 하는 것 같군요..!ㅎㅎ) - 아래 결과를 확인하면, 티켓의 class가 높을수록 생존율이 증가하는 을 확인할 수 있습니다.
df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar()결과

위 그래프를 보면서 알 수 있는점은 클래스가 높을수록 생존률이 높다는 것 입니다.
'Pclass'가 생존에 큰 영향을 미친다는 것을 알 수 있군요!
아래 코드는 2개의 차트를 그립니다.
1번 차트는 bar plot을 사용해 티켓 클래스 별 count 합산을,
2번 차트는 count plot을 사용하여 티켓 클래스와 생존 그래프를 나타내었습니다.
f, ax = plt.subplots(1,2, figsize=(14, 4))
bars = df_train['Pclass'].value_counts().plot.bar(color=['#CD7F32', '#FFDF00', '#D3D3D3'], ax=ax[0])
ax[0].set_title('Number of Passengers By Pclass', y=1.02)
ax[0].set_ylabel('Count')
sns.countplot(x='Pclass', hue='Survived', data=df_train, ax=ax[1])
ax[1].set_title('Pclass: Survived vs Dead', y=1.02)
plt.show()
결과

위 그래프를 보면서, 클래스가
코드 설명
1. f, ax = plt.subplots(1,2, figsize=(14, 4)) 또 나왔네요.
첫번째 줄은 f (figure 그래프를 그릴 객체) , ax (Axes 축) 객체에 matplotlib.pyplot 모듈을 사용한 subplot 그래프를 1행 2열에 그리고, 사이즈는 14, 4(가로 14 inch, 세로 4 inch)로 그립니다.
2. bars = df_train['Pclass'].value_counts().plot.bar(color=['#CD7F32', '#FFDF00', '#D3D3D3'], ax=ax[0])
df_train['Pclass'] - 'Pclass' 컬럼을 선택합니다.
value_counts()함수는 열에있는 unique한 모든 고유 값을 count해주는 함수로, 1,2,3 각 값의 합을 반환해줍니다.
plot.bar() 이 데이터를 가지고 bar 그래프를 그리는데, 색깔은 3가지 색상을 사용합니다. #CD7F32', '#FFDF00', '#D3D3D3'
ax=ax[0] 이 그래프는 [0] 번째 왼쪽에 그려집니다. (1행, 2열) 중 1열에 들어가게 됩니다. [0] = 1열(1번째), [1] = 2열(2번째)
3. ax[0].set_title('Number of Passengers By Pclass', y=1.02) - set_title() :제목 설정 및 y=1.02 제목의 기본 위치에 대한 상대적인 수직 위치를 제어합니다. (제목의 위치를 살~짝 위로 올려줍니다. 그래프 높이가 클수록 영향이 커집니다.)
ax[0].set_ylabel('Count') - set_ylabel() y축 라벨 이름을 count로 명명합니다.
sns.countplot(x='Pclass', hue='Survived', data=df_train, ax=ax[1]) x축에 Pclass 컬럼을 넣고, hue는 다른 카테고리 변수를 사용하여 데이터를 색상으로 구분하도록 지시합니다. 여기서는 'Survived' (생존 여부) 변수를 사용하여 생존 (예: 파란색)과 사망 (예:빨강색)을 구분하여 나타낼 수 있습니다.
4. ax[1].set_title('Pclass: Survived vs Dead', y=1.02) ax[1] 그래프의 이름을 명명합니다. 제목의 위치를 살짝 수정합니다.
5. plt.show() 그래프를 그립니다.
이제 조금씩 코드가 보이는 것 같네요! 계속 반복되는 패턴이 있습니다. 다음 그래프를 봅시다.
이번엔 성별과 생존 컬럼의 관계를 확인합니다.
2-2. Sex 성별
코드
f, ax = plt.subplots(1,2, figsize=(14,6))
df_train[['Sex', 'Survived']].groupby(['Sex'], as_index=True).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived vs Sex')
sns.countplot(x='Sex', hue='Survived', data=df_train, ax=ax[1])
ax[1].set_title('Sex: Survived vs Dead')
plt.show()
결과

- 결과를 확인하면 여성의 생존율이 압도적으로 높다는 것을 알 수 있습니다.
코드 확인
f, ax = plt.subplots(1,2, figsize=(14,6)) - 1행 2열의 그래프 그리드 생성, 사이즈는 14, 6inch.
df_train[['Sex', 'Survived']].groupby(['Sex'], as_index=True).mean().plot.bar(ax=ax[0]) - 성별 컬럼과 생존 컬럼을 선택하고, ' Sex ' 컬럼을 그래프의 x축 라벨로 사용하고 싶을 때 사용합니다.
ax[0].set_title('Survived vs Sex') - 이름을 명명합니다.
sns.countplot(x='Sex', hue='Survived', data=df_train, ax=ax[1]) - countplot을 사용하고, x축에 성별 축을 넣고, hue에 생존 컬럼을 넣고, data에는 df_train 값을 넣습니다. 2번째 그래프 축에 넣어줍니다.
ax[1].set_title('Sex: Survived vs Dead') - 2번째 그래프의 이름을 명명하고,
plt.show() - 그래프를 그립니다.
코드
df_train[['Sex', 'Survived']].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)
결과

(성별과 생존율 사이의 관계인데, 0.742 + 0.188 = 0.93이다. 나머지 0.07은 어디로 간걸까? 라는 질문이 생겼지만, 남자 생존율과 여자 생존율은 독립적인 관계라는걸 깨달았는데, 남자의 생존율 + 사망율 =1, 여자의 생존율 + 사망율 = 1이었습니다.)
코드
pd.crosstab(df_train['Sex'], df_train['Survived'], margins=True).style.background_gradient(cmap='summer_r')
결과

- 성별이 생존율에 큰 영향을 끼치는 것을 알 수 있습니다.
코드 해석
pandas 모듈의 crosstab 표로 성별과 생존여부를 margins 옵션을 True로 주어서 소계까지 나오도록 하였습니다.
또한, style.background_gradient(cmap='summer_r')
2-3. Both Sex and Pclass 성별과티켓 클래스
코드
sns.catplot(x='Sex', y='Survived', col='Pclass', data=df_train, saturation= 0.5, kind='point', height=9, aspect=1)
결과
- 성별과 Pclass에 따라 생존율이 어떻게 변화하는지 나타내는 그래프 입니다.
- 1등석에 탄 여성들은 생존율이 1에 가깝다는 것을 확인할 수 있습니다.
- 또한 클래스에 상관없이 여성이 생존율이 높다는 것을 알 수 있습니다.

코드 확인
- seaborn 의 catplot 은 2차원 그래프를 사용해 x, y, col을 사용해서 3가지를 분석할 수 있군요!
- size를 입력하면 아래와 같은 에러가 납니다. size 옵션이 사라진 것 같아서 구글링을 통해 찾아보니, 캐글 필사코드는 sns.factorplot 2023년에 이름이 factorplot에서 catplot으로 바뀌었다는 것을 알 수 있었습니다.
AttributeError: Line2D.set() got an unexpected keyword argument 'size'- seaborn.catplot API를 찾아본 결과 size는 height로 바뀌었다. size라는 표현이 모호하고, height가 더 적절한 설명이라 변경된 것 처럼 보입니다.
참 속도가 느린 것 같지만..^^; 익숙해지는 시간이라 생각하고, 한걸음 한걸음 나아가야겠습니다.
'IT > 캐글' 카테고리의 다른 글
| [캐글] 타이타닉 - 탐색적 데이터 분석(EDA) 정리 (0) | 2024.06.07 |
|---|---|
| [캐글] 처음 시작하는 캐글 - 타이타닉(4) (0) | 2024.06.04 |
| [캐글] 처음 시작하는 캐글 - 타이타닉(3) (0) | 2024.05.29 |
| [캐글] 처음 시작하는 캐글 - 타이타닉(2) (0) | 2024.05.28 |
| [캐글] 처음 시작하는 캐글 - 타이타닉 (0) (0) | 2024.05.21 |



