[캐글] 처음 시작하는 캐글 - 타이타닉(4)
타이타닉 5번째네요. 코드를 한 줄 한 줄 보는 것이 시간이 오래걸리긴해도, 익숙해지는 것을 목적으로 끝까지 마무리해보려고 합니다!
이 글은 이유한님의 글을 참고하며 캐글 필사를 해보면서
유한님의 정리가 깔끔해서 그것들을 참고하고 있습니다.
(출처: 캐글 코리아 홈페이지의 이유한 님의 글)
3. Feature engineering
3.1. fill null data
AGE 채우기
- null data 를 어떻게 채우느냐에 따라 모델의 성능이 좌지우지될 수 있어 중요한 요소입니다.
- 이름을 통해 Age를 채워 넣습니다. 이름으로 나이를 유추할 수 있음. (이름과의 관계를 통해 age를 채우는 방법!)
- 여기서 이름을 추출하여 'Initial' 변수에 replace()함수로 주요한 특징 5가지로 (Mr, Mrs, Miss, Master, Other) replace 해줍니다.
코드
df_train['Initial']= df_train.Name.str.extract('([A-Za-z]+)\.')df_train['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don', 'Dona'],
['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr', 'Mr'],inplace=True)
코드
# 원래 코드
df_train.groupby('Initial').mean()
# numeric_only=True를 넣어줘야 문자열 값에 대해 평균을 구하지 않습니다..!!!
groupby('columns').mean(numeric_only=True)
여기서 코랩으로 실행하다가 오류가 나서 한참을 헤메고, 알고보니... 옵션이 달라진 것 같아요.
(옛날에는 오류가 나지 않았던 모양입니다.) numeric_only=True 을 넣어야 합니다.

결과

- Age의 평균을 이용해 Null value 를 채우도록 하겠습니다.
- pandas dataframe 을 다룰 때에는 boolean array를 이용해 indexing 하는 방법이 참으로 편리합니다.
- 아래 코드 첫줄을 해석하자면, isnull() 이면서 Initial 이 Mr 인 조건을 만족하는 row(탑승객) 의 'Age' 의 값을 33으로 치환한다 입니다.
- (loc + boolean + column 을 사용해 값을 치환하는 방법은 자주 쓰이므로 꼭 익숙해집시다.)
코드
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Mr'),'Age'] = 33
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Mrs'),'Age'] = 36
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Master'),'Age'] = 5
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Miss'),'Age'] = 22
df_train.loc[(df_train.Age.isnull())&(df_train.Initial=='Other'),'Age'] = 46
fill null in Embarked
- Embarked 항목은 큰 연관성이 없음, 대부분 'S' 이므로, 'S'로 채운다. (몇 개 안되어서 큰 영향을 미치지는 못함.)
'Embarked' 항목의 널값을 확인!
print('Embarked has ', sum(df_train['Embarked'].isnull()), ' Null values')
채워줍니다
df_train['Embarked'].fillna('S', inplace=True)
나이도
3.2. Change Age (연속된 값으로 범주화)
- 10살 단위로 끊어서 0 - 10살 = 1 , 11 - 20살 = 2, 21 - 30살 = 3, 31 - 40살 = 4 ... 이런식으로 변경합니다.
(continuous to categorical)
def category_age(x):
if x < 10:
return 0
elif x < 20:
return 1
elif x < 30:
return 2
elif x < 40:
return 3
elif x < 50:
return 4
elif x < 60:
return 5
elif x < 70:
return 6
else:
return 7
df_train['Age_cat_2'] = df_train['Age'].apply(category_age)
3. Change Initial, Embarked and Sex (str 에서 숫자로)
- 현재 Initial 은 Mr, Mrs, Miss, Master, Other 총 5개로 이루어져 있는데, 이런 카테고리로 표현되어져 있는 데이터를 모델에 인풋으로 넣어줄 때 우리가 해야할 것은 먼저 컴퓨터가 인식할 수 있도록 수치화 시켜야 한다.
# Initial
df_train['Initial'] = df_train['Initial'].map({'Master': 0, 'Miss': 1, 'Mr': 2, 'Mrs': 3, 'Other': 4})
df_test['Initial'] = df_test['Initial'].map({'Master': 0, 'Miss': 1, 'Mr': 2, 'Mrs': 3, 'Other': 4})
# Embark
df_train['Embarked'] = df_train['Embarked'].map({'C': 0, 'Q': 1, 'S': 2})
# Sex
df_train['Sex'] = df_train['Sex'].map({'female': 0, 'male': 1})
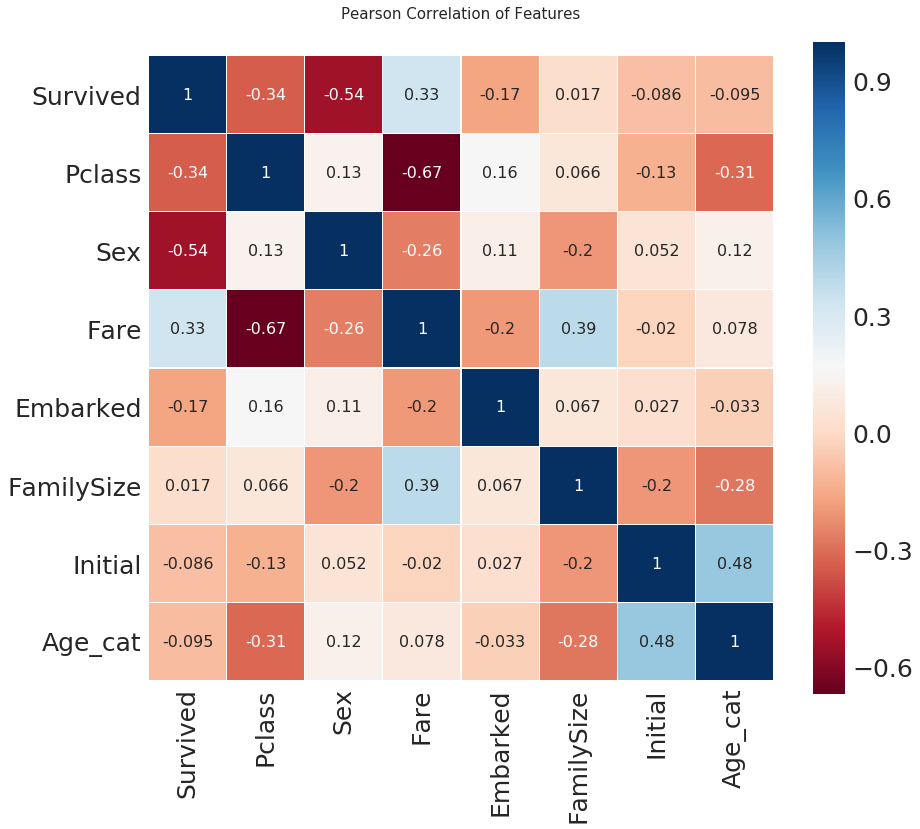
매트릭스 형태의 heatmap plot
코드
heatmap_data = df_train[['Survived', 'Pclass', 'Sex', 'Fare', 'Embarked', 'FamilySize', 'Initial', 'Age_cat']]
colormap = plt.cm.RdBu
plt.figure(figsize=(14, 12))
plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(heatmap_data.astype(float).corr(), linewidths=0.1, vmax=1.0,
square=True, cmap=colormap, linecolor='white', annot=True, annot_kws={"size": 16})
del heatmap_data
- 우리는 여러 feature 를 가지고 있으니 이를 하나의 maxtrix 형태로 보면 편할 텐데, 이를 heatmap plot 이라고 하며, dataframe 의 corr() 메소드와 seaborn 을 가지고 편하게 그릴 수 있습니다.
- 우리가 EDA에서 살펴봤듯이, Sex 와 Pclass 가 Survived 에 상관관계가 어느 정도 있음을 볼 수 있습니다.
- 생각보다 fare 와 Embarked 도 상관관계가 있음을 볼 수 있습니다.
- 또한 우리가 여기서 얻을 수 있는 정보는 서로 강한 상관관계를 가지는 feature들이 없다는 것입니다.
- 이것은 우리가 모델을 학습시킬 때, 불필요한(redundant, superfluous) feature 가 없다는 것을 의미합니다. 1 또는 -1 의 상관관계를 가진 feature A, B 가 있다면, 우리가 얻을 수 있는 정보는 사실 하나일 거니까요.
- 이제 실제로 모델을 학습시키기 앞서서 data preprocessing (전처리)을 진행합니다.
3.4 One-hot encoding on Initial and Embarked
모델의 성능을 높이기 위해서는 원 핫 인코딩이라는 것을 해야합니다.
이는 컴퓨터 또는 기계는 문자보다는 숫자를 더 잘 처리 할 수 있는데, 이를 위해 자연어 처리에서는 문자를 숫자로 바꾸는 여러가지 기법 중 원-핫 인코딩(One-Hot Encoding)은 그 많은 기법 중 가장 기본적인 표현 방법 입니다.
pd.get_dummies() 함수를 사용해서 원 핫 인코딩을 합니다.
df_train = pd.get_dummies(df_train, columns=['Initial'], prefix='Initial')
df_test = pd.get_dummies(df_test, columns=['Initial'], prefix='Initial')
원 핫 인코딩은 이렇게 생긴 Initial 칼럼이 Initial_0부터 Initial_4까지 새로 생깁니다.
모델을 잘 학습시킬 수 있도록 0 혹은 1의 값으로 변경해야합니다.

Embarked 컬럼도 동일하게 적 해줍니다.
df_train = pd.get_dummies(df_train, columns=['Embarked'], prefix='Embarked')
df_test = pd.get_dummies(df_test, columns=['Embarked'], prefix='Embarked')
이제 학습에 필요하지 않은 모든 컬럼을 삭제해줍니다.
코드
df_train.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Cabin'], axis=1, inplace=True)
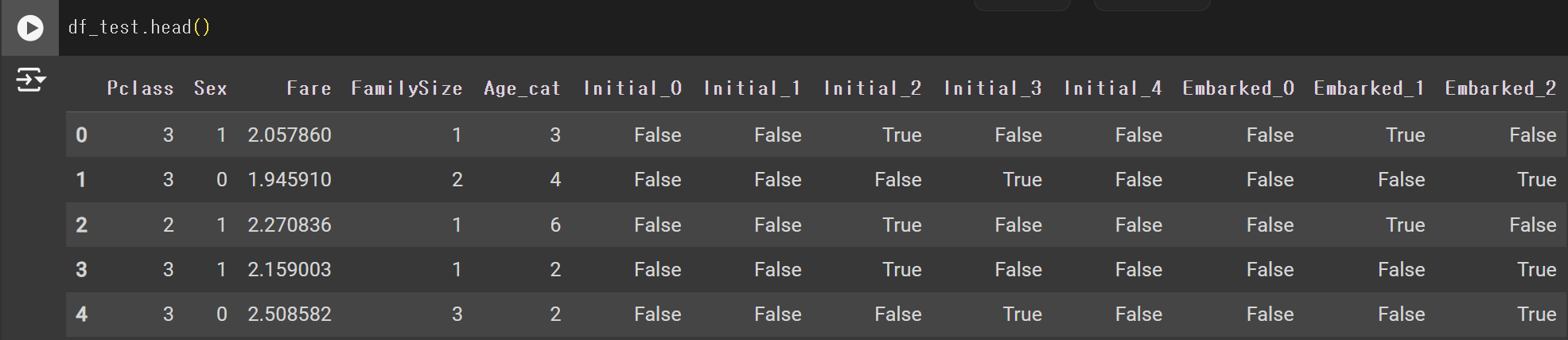
df_test.drop(['PassengerId', 'Name', 'SibSp', 'Parch', 'Ticket', 'Cabin'], axis=1, inplace=True)df_train.head()결과
이제 거의 끝입니다. 모델을 만들고 학습을 시켜줍니다.
#importing all the required ML packages
from sklearn.ensemble import RandomForestClassifier # 유명한 randomforestclassfier 입니다.
from sklearn import metrics # 모델의 평가를 위해서 씁니다
from sklearn.model_selection import train_test_split # traning set을 쉽게 나눠주는 함수입니다.
코드
# 데이터 분리: 타이타닉 훈련 데이터셋(df_train)에서 특징(X_train)과 레이블(target_label)을 분리합니다.
X_train = df_train.drop('Survived', axis=1).values
target_label = df_train['Survived'].values
# 테스트 데이터 준비: 별도의 테스트 데이터셋(df_test)을 모델 입력 형태(X_test)로 변환합니다.
X_test = df_test.values# 데이터 분할: train_test_split 함수를 사용하여 훈련 데이터(X_train, target_label)를 훈련 세트(X_tr, y_tr)와 검증 세트(X_vld, y_vld)로 나눕니다.
# 비율 설정: 검증 세트의 비율을 30%로 설정하여 데이터를 분할합니다.
# 난수 시드 고정: random_state 값을 고정하여 결과를 재현 가능하도록 합니다.
X_tr, X_vld, y_tr, y_vld = train_test_split(X_train, target_label, test_size=0.3, random_state=2018)
이렇게 전처리를 하고 3줄이면 훈련이 된다니 참 신기합니다.
model = RandomForestClassifier()
model.fit(X_tr, y_tr)
prediction = model.predict(X_vld)
모델 성능 살펴보기

수 많은 차트 그리는 방법들... 모두 정리를 한번 해봐야겠어요.
from pandas import Series
feature_importance = model.feature_importances_
Series_feat_imp = Series(feature_importance, index=df_test.columns)plt.figure(figsize=(8, 8))
Series_feat_imp.sort_values(ascending=True).plot.barh()
plt.xlabel('Feature importance')
plt.ylabel('Feature')
plt.show()

이제 제출 해 볼 시간!
submission = pd.read_csv('../input/gender_submission.csv')
submission.head()
이런 모습으로 나옵니다.
prediction = model.predict(X_test)
submission['Survived'] = predictionsubmission.to_csv('./my_first_submission.csv', index=False)- 이제 캐글에 제출해보도록 합시다.
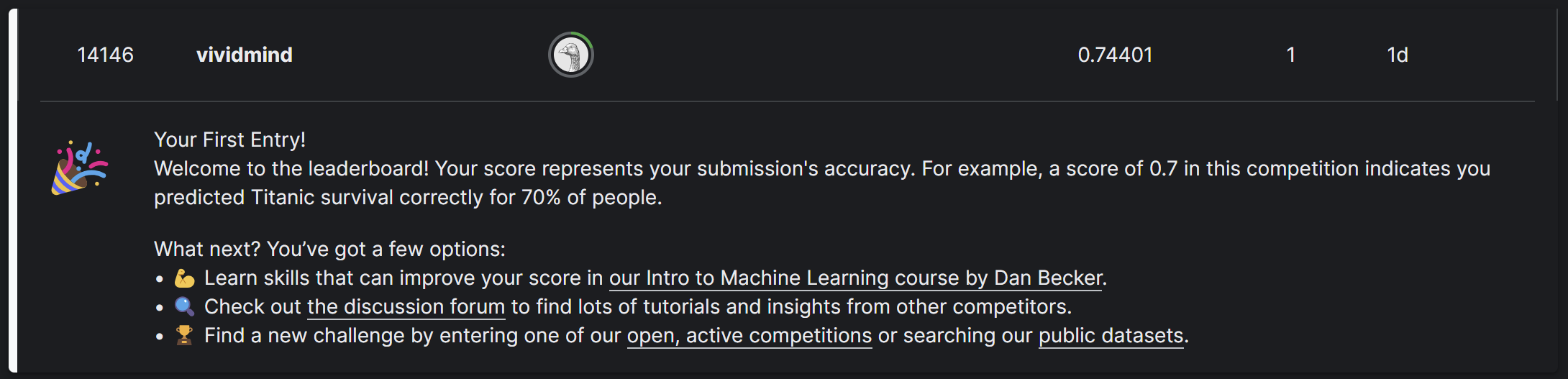
첫번째 필사를 그대로 제출해서 14146등 했군요!ㅋㅋㅋ
우선 캐글 첫번째 경험을 통해 친근해진것만 같습니다..ㅎㅎㅎ
앞으로 그래프를 그리는 방법과, 어떻게 더 정확도를 높이는지도 알아봐야겠습니다.
이제부터는 생각하는 공부겠네요!